A generative action policy must capture (1) multimodal actions, (2) run in real time, and (3) improve through RL. Few-step diffusion/flow policies largely solve the first two; the remaining tension is RL post-training. Given a current state $s$, they generate an action $a$ by integrating a time-indexed velocity field along an ODE trajectory:
In RL fine-tuning, the reward signal $Q_\phi(s, a)$ is defined on the final executed action $a = x_1$, yet the policy is parameterized by the intermediate velocities $v_\theta(x_t, t, s)$ along the whole trajectory. This raises a hard output-to-trajectory credit assignment problem:
"Which intermediate velocity should receive how much credit?"
Crucially, this burden persists even for one-step diffusion variants (MeanFlow, Consistency Models): sampling is one-step, but training remains trajectory-level, since all intermediate shortcuts must align with the same endpoint.
DFP and few-step diffusion/flow policies both map noise to an action in a single pass, but parameterize that map differently. Two structural consequences make the non-ODE drifting policy especially suited to RL fine-tuning:
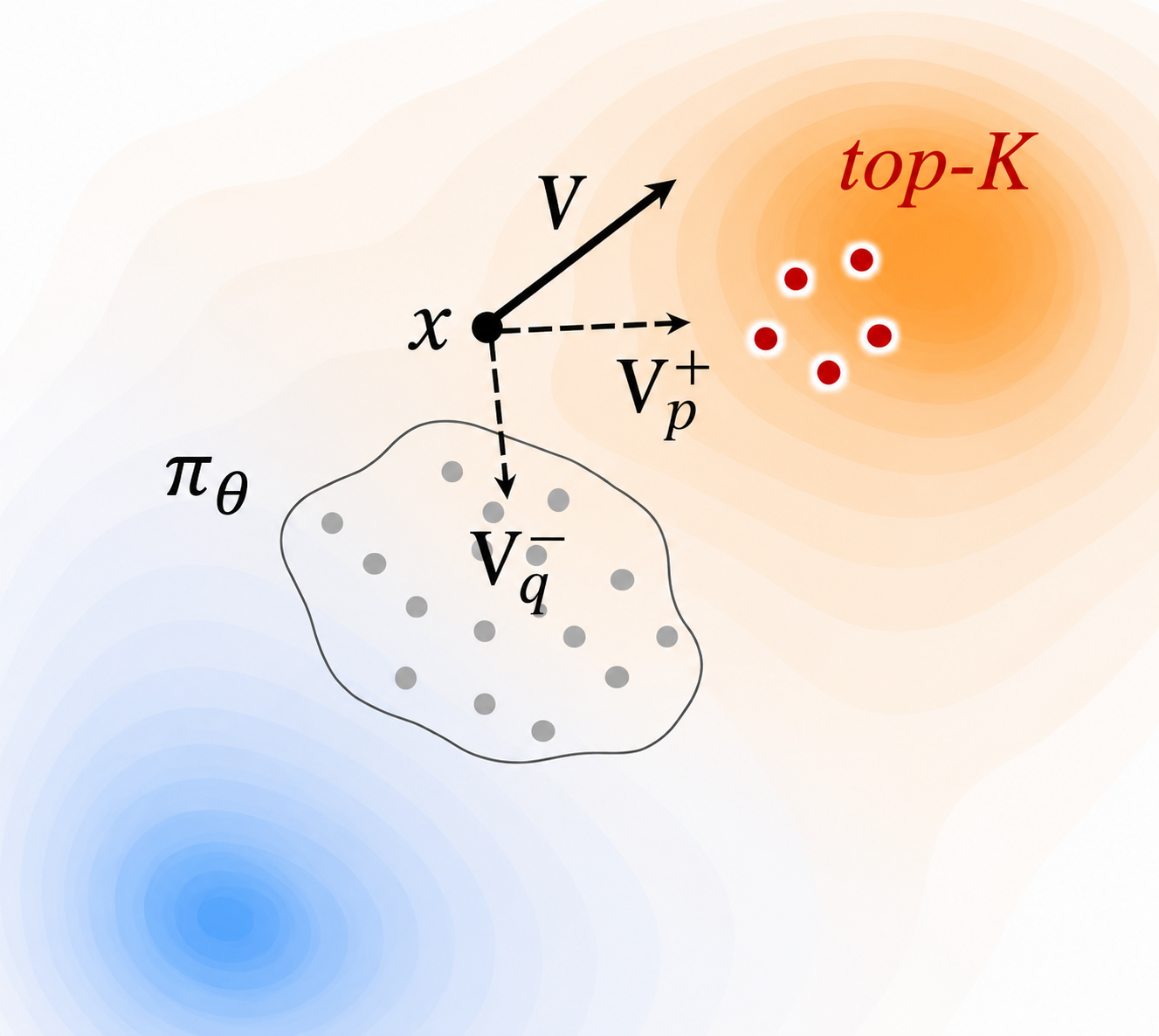
Built on drifting models (Deng et al., 2026), Drifting Field Policy (DFP) directly parameterizes the action distribution with a single-pass pushforward map $f_\theta$, with no time variable and no ODE trajectory.
A single forward pass maps a noise sample directly to an action. Compared to ODE-based generation, this gives (i) one-step action generation and (ii) no ODE trajectory → no output-to-trajectory credit assignment.
Let $p$ be a target distribution and $q := [f_\theta]_\# p_\epsilon$ the pushforward distribution. The drifting field moves generated particles $x$ toward positives $p$ and away from negatives $q$, built from kernel mean shifts:
Here $k(\cdot,\cdot)$ is a similarity kernel, e.g., the Gaussian kernel $k(x,y) = \exp\!\left(-\|x-y\|^2 / 2h^2\right)$.
$f_\theta$ is trained by fixed-point regression that drives the drifting field to zero (with a stop-gradient on the drifted target), so that $q \to p$. This gives the general drifting training objective, defined for any target/source pair $(p, q)$:
Since $\mathcal{L}_{\mathrm{drift}}$ is parameterized by the positive (target) $p$ and the negative (source) $q$, the same objective applies to any choice of $(p, q)$ — a flexibility we exploit next by plugging in different targets for policy improvement and behavior cloning.
RL fine-tuning targets the reward-tilted policy
Policy improvement is then just the general drift objective $\mathcal{L}_{\mathrm{drift}}$ from (B), instantiated with the negative source $q = \pi_\theta$ and the positive target $p = \pi^{+}$ (whereas $p = p_{\mathrm{data}}$ recovers behavior cloning):
This decomposition follows in two steps:
The ideal target $\pi^{+}$ is intractable due to the normalizing constant $Z(s)$. DFP approximates it with an empirical top-$K$ set of high-value actions sampled from $\pi_{\mathrm{old}}$:
Practically, each update proceeds in four steps:
In practice, this top-$K$ loss is what we optimize — effectively behavior cloning on the top-$K$ critic-selected actions, with a bounded approximation error to the ideal update $\mathcal{L}_{\mathrm{PI}}$. (See the paper for more details.)
Across 12 Robomimic and OGBench manipulation tasks (offline-to-online RL), DFP outperforms both multi-step and one-step diffusion/flow policies, reaching the best average success rate with single-pass inference (+15.5 pp over its closest baseline, MVP).
Success rate (%) on Robomimic and OGBench tasks under the offline-to-online RL setting. Each cell reports the mean over 5 seeds. Best results are shown in bold; second-best results are underlined.
| Method | Robomimic | Cube-double | Cube-triple | Cube-quadruple-100m | Avg. | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| lift | square | can | task2 | task3 | task4 | task2 | task3 | task4 | task2 | task3 | task4 | ||
| BFN | 97.6±2 | 32.8±8 | 82.0±2 | 86.0±5 | 88.8±5 | 27.2±8 | 7.6±9 | 6.8±3 | 0.0±0 | 32.4±21 | 0.0±0 | 0.0±0 | 38.4 |
| QC-BFN | 99.6±1 | 88.4±4 | 90.6±3 | 99.8±0 | 99.8±0 | 92.6±6 | 87.4±10 | 80.8±4 | 33.4±9 | 95.8±2 | 63.2±10 | 74.2±11 | 83.8 |
| FQL | 96.8±2 | 10.8±7 | 58.4±8 | 93.2±8 | 91.2±5 | 6.0±6 | 0.4±1 | 6.4±8 | 0.0±0 | 0.0±0 | 0.0±0 | 0.0±0 | 30.3 |
| QC-FQL | 100.0±0 | 72.0±9 | 94.4±2 | 100.0±0 | 99.8±0 | 99.8±0 | 88.2±2 | 60.4±12 | 51.4±24 | 98.0±2 | 85.0±7 | 92.2±7 | 86.8 |
| MVP | 99.8±0 | 79.4±4 | 83.6±5 | 98.4±1 | 98.6±1 | 94.8±4 | 86.2±4 | 57.2±10 | 31.0±20 | 96.6±2 | 47.2±30 | 91.2±2 | 80.3 |
| DFP (Ours) | 100.0±0 | 93.2±2 | 90.6±3 | 100.0±0 | 99.6±1 | 99.6±1 | 98.4±1 | 91.6±2 | 81.2±6 | 99.6±1 | 96.6±2 | 99.0±2 | 95.8 |
Gray and white background indicate offline and online phases, respectively. DFP not only attains a higher final success rate but also converges faster.

With $N = 16$, DFP is robust across $K$, with the best performance at $K = 4$. All DFP variants outperform MVP (80.3 avg.).
| $K$ (of $N=16$) | Robo. | Cube-2. | Cube-3. | Cube-4. | Avg. |
|---|---|---|---|---|---|
| $K = 1$ | 95.0 | 99.7 | 54.5 | 94.2 | 85.8 |
| $K = 2$ | 94.6 | 100.0 | 76.2 | 96.8 | 91.9 |
| $K = 4$ | 93.9 | 99.7 | 90.4 | 98.4 | 95.6 |
| $K = 8$ | 88.6 | 99.8 | 85.5 | 96.2 | 92.5 |
Representative DFP rollouts on Robomimic and OGBench manipulation tasks.
@article{koo2026driftingfieldpolicy,
title={Drifting Field Policy: A One-Step Generative Policy via Wasserstein Gradient Flow},
author={Koo, Juil and Park, Mingue and Choi, Jiwon and Min, Yunhong and Sung, Minhyuk},
journal={arXiv preprint arXiv:2605.07727},
year={2026}
}